It is only our conception of time that makes us call the Last Judgement by this name. It is, in fact, a kind of martial law. — Franz Kafka
在前面的文章中,我們一直圍繞著建立模型的迭代實驗過程進行討論,也提到了一個能在產業環境表現良好的模型該達到什麼標準。
而當經過數次迴圈得到不錯的模型之後,其實還可以再做一次深度的錯誤分析來對系統進行最後評斷以確保它的可行性:
*圖片修改自 MLEP, Selecting and training a model — Key challenges
那在最終評斷 (Final audit) 中還需要注意什麼呢?
讓我們看看其中有什麼眉角吧!!
通常高階指標 (Metric) 很容易把模型在某些特定資料上發生的問題隱藏起來,而對那些資料來說,不管高階指標表現多好,得到的預測值都會是很差的。
如果將這個模型部署到產品端,使用者體驗肯定也不會太好,因此在部署前最好再對模型表現進行一次深入的分析。
最終評斷的流程如下 (檢查準確度、公平性/偏見與其他問題):
集思廣益找出系統可能出錯的地方,例如檢視:
可以先從達成三個里程碑會遇到的問題開始檢查 (參考 [Day 09] 建立機器學習模型 — Andrew Ng 大神說要這樣做)。
但實際上會出現的錯誤依產業別會有很大的不同,特別是對於公平性與偏見的標準還很不一致,所以要將這兩點考量銘記在心。
以語音辨識為例,可以檢視:
建立可以在這些錯誤發生時正確評判模型表現的指標,並施加在對應的資料子集上。
以語音辨識為例,可以建立以下指標:
找出適當的指標之後,MLOps 工具可以幫助我們自動觸發驗證流程,例如 TensorFlow Model Analysis (TFMA) 就能在不同資料子集上詳細計算各種指標。
說服老闆這些問題很值得擔心,以及這些指標可以用來解決問題。
為了揪出被隱藏在高階指標之下的問題,可以使用 TensorFlow Model Analysis (TFMA) 針對模型在不同資料切片上的表現進一步分析,其粗略架構如下圖: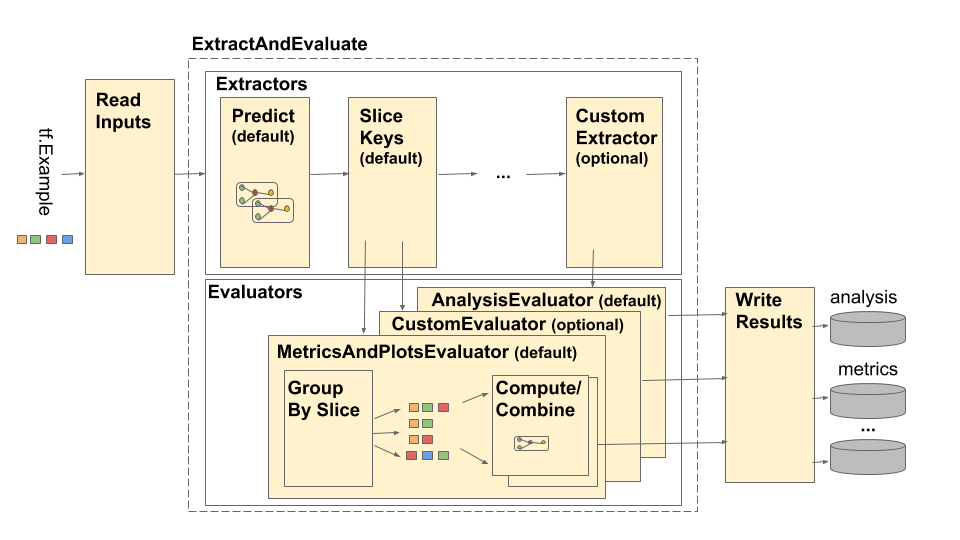
*圖片來源:Tensorflow Model Analysis Architecture
TFMA Pipeline 由四個主要部件組合而成:
tfma.extracts。SliceKeyExtractor 將原始資料集拆分成不同切片以供 PredictExtractor 進行預測,其結果再次以 tfma.extracts 字典的形式傳到下一個階段。MetricsAndPlotsEvaluator 會擷取所需的資料並搭配從前一階段收到的預測值來評估模型表現,這步驟可以使用多種 Evaluator,甚至可以自創符合需求的 Evaluator。可以發現 TFMA 其實跟我們比較熟悉的 TensorBoard 功能有點像,兩者都可以用來分析模型的表現,主要差別在於兩者進行運算的對象與時間點不同,這會造成用途上的差別如下:
而各個不同處的詳細解說請參考 Introducing TensorFlow Model Analysis,但從以下示意圖就可以看出 TensorBoard 主要處理來自 checkpoints 的流動指標 (streaming metrics),而 TFMA 則專注於處理輸出的 SavedModel:
*圖片來源:Introducing TensorFlow Model Analysis
以上就是今天的內容啦,明天就是 Modeling 的最後一篇文章,要來講實驗管理,明天見囉。


 iThome鐵人賽
iThome鐵人賽